

- Ingest data into a : load data from Twelve Data into your database.
- Query your dataset: create candlestick views, query the aggregated data, and visualize the data in Grafana.
- Compress your data using : learn how to store and query your financial tick data more efficiently using compression feature of .
OHLCV data and candlestick charts
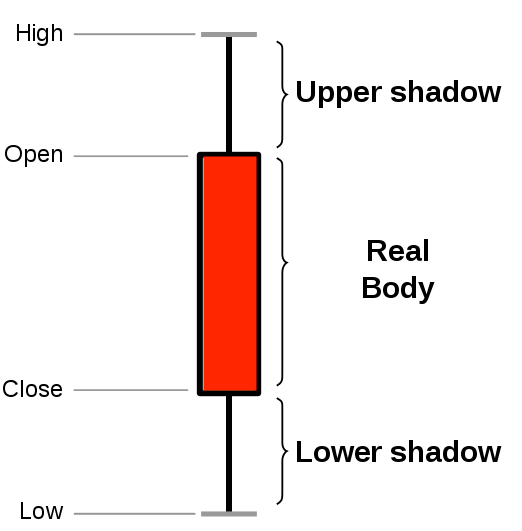
The financial sector regularly uses candlestick charts to visualize the price change of an asset. Each candlestick represents a time period, such as one minute or one hour, and shows how the asset’s price changed during that time. Candlestick charts are generated from the open, high, low, close, and volume data for each financial asset during the time period. This is often abbreviated as OHLCV:- Open: opening price
- High: highest price
- Low: lowest price
- Close: closing price
- Volume: volume of transactions
 is well suited to storing and analyzing financial candlestick data,
and many community members use it for exactly this purpose. Check out
these stories from some community members:
is well suited to storing and analyzing financial candlestick data,
and many community members use it for exactly this purpose. Check out
these stories from some community members:
- How Trading Strategy built a data stack for crypto quant trading
- How Messari uses data to open the cryptoeconomy to everyone
- How I power a (successful) crypto trading bot with
Prerequisites
To follow the steps on this page:- Create a target with the Real-time analytics capability enabled. You need your connection details. This procedure also works for .
Ingest data into a service
This tutorial uses a dataset that contains second-by-second trade data for the most-traded crypto-assets. You optimize this time-series data in a calledcrypto_ticks.
You also create a separate table of asset symbols in a regular table named crypto_assets.
The dataset is updated on a nightly basis and contains data from the last four
weeks, typically around 8 million rows of data. Trades are recorded in
real-time from 180+ cryptocurrency exchanges.
Optimize time-series data in a hypertable
s are tables in that automatically partition your time-series data by time. Time-series data represents the way a system, process, or behavior changes over time. s enable to work efficiently with time-series data. Each is made up of child tables called chunks. Each chunk is assigned a range of time, and only contains data from that range. When you run a query, identifies the correct chunk and runs the query on it, instead of going through the entire table. is the hybrid row-columnar storage engine in used by . Traditional databases force a trade-off between fast inserts (row-based storage) and efficient analytics (columnar storage). eliminates this trade-off, allowing real-time analytics without sacrificing transactional capabilities. dynamically stores data in the most efficient format for its lifecycle:- Row-based storage for recent data: the most recent chunk (and possibly more) is always stored in the , ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a writethrough for inserts and updates to columnar storage.
- Columnar storage for analytical performance: chunks are automatically compressed into the , optimizing storage efficiency and accelerating analytical queries.
- Connect to your In open an SQL editor. You can also connect to your service using psql.
-
Create a to store the real-time cryptocurrency data
Create a for your time-series data using CREATE TABLE.
For efficient queries on data in the , remember to
segmentbythe column you will use most often to filter your data:If you are self-hosting v2.19.3 and below, create a relational table, then convert it using create_hypertable. You then enable with a call to ALTER TABLE.
Create a standard Postgres table for relational data
When you have relational data that enhances your time-series data, store that data in standard relational tables.-
Add a table to store the asset symbol and name in a relational table
crypto_ticks, and a normal
table named crypto_assets.
Load financial data
This tutorial uses real-time cryptocurrency data, also known as tick data, from Twelve Data. To ingest data into the tables that you created, you need to download the dataset, then upload the data to your .-
Unzip crypto_sample.zip to a
<local folder>. This test dataset contains second-by-second trade data for the most-traded crypto-assets and a regular table of asset symbols and company names. To import up to 100GB of data directly from your current -based database, migrate with downtime using native tooling. To seamlessly import 100GB-10TB+ of data, use the live migration tooling supplied by . To add data from non- data sources, see Import and ingest data. -
In Terminal, navigate to
<local folder>and connect to your .The connection information for a is available in the file you downloaded when you created it. -
At the
psqlprompt, use theCOPYcommand to transfer data into your . If the.csvfiles aren’t in your current directory, specify the file paths in these commands:Because there are millions of rows of data, theCOPYprocess could take a few minutes depending on your internet connection and local client resources.
Connect Grafana to Tiger Cloud
To visualize the results of your queries, enable Grafana to read the data in your :-
Log in to Grafana
In your browser, log in to either:
- Self-hosted Grafana: at
http://localhost:3000/. The default credentials areadmin,admin. - Grafana Cloud: use the URL and credentials you set when you created your account.
- Self-hosted Grafana: at
-
Add your as a data source
-
Open
Connections>Data sources, then clickAdd new data source. -
Select
PostgreSQLfrom the list. -
Configure the connection:
-
Host URL,Database name,Username, andPasswordConfigure using your connection details.Host URLis in the format<host>:<port>. -
TLS/SSL Mode: selectrequire. -
PostgreSQL options: enableTimescaleDB. - Leave the default setting for all other fields.
-
-
Click
Save & test.
-
Open
Query the data
Turning raw, real-time tick data into aggregated candlestick views is a common task for users who work with financial data. includes hyperfunctions that you can use to store and query your financial data more easily. Hyperfunctions are SQL functions within that make it easier to manipulate and analyze time-series data in with fewer lines of code. There are three hyperfunctions that are essential for calculating candlestick values:time_bucket(), FIRST(), and LAST().
The time_bucket() hyperfunction helps you aggregate records into buckets of
arbitrary time intervals based on the timestamp value. FIRST() and LAST()
help you calculate the opening and closing prices. To calculate highest and
lowest prices, you can use the standard aggregate functions MIN and
MAX.
In , the most efficient way to create candlestick views is to use
continuous aggregates.
In this tutorial, you create a continuous aggregate for a candlestick time
bucket, and then query the aggregate with different refresh policies. Finally,
you can use Grafana to visualize your data as a candlestick chart.
Create a continuous aggregate
To look at OHLCV values, the most effective way is to create a continuous aggregate. In this tutorial, you create a continuous aggregate to aggregate data for each day. You then set the aggregate to refresh every day, and to aggregate the last two days’ worth of data. Creating a continuous aggregate- Connect to the that contains the Twelve Data cryptocurrency dataset.
-
At the psql prompt, create the continuous aggregate to aggregate data every
minute:
When you create the continuous aggregate, it refreshes by default.
-
Set a refresh policy to update the continuous aggregate every day,
if there is new data available in the for the last two days:
Query the continuous aggregate
When you have your continuous aggregate set up, you can query it to get the OHLCV values. Querying the continuous aggregate- Connect to the that contains the Twelve Data cryptocurrency dataset.
-
At the psql prompt, use this query to select all Bitcoin OHLCV data for the
past 14 days, by time bucket:
The result of the query looks like this:
Graph OHLCV data
When you have extracted the raw OHLCV data, you can use it to graph the result in a candlestick chart, using Grafana. To do this, you need to have Grafana set up to connect to your instance.- Ensure you have Grafana installed, and you are using the TimescaleDB database that contains the Twelve Data dataset set up as a data source.
-
In Grafana, from the
Dashboardsmenu, clickNew Dashboard. In theNew Dashboardpage, clickAdd a new panel. -
In the
Visualizationsmenu in the top right corner, selectCandlestickfrom the list. Ensure you have set the Twelve Data dataset as your data source. -
Click
Edit SQLand paste in the query you used to get the OHLCV values. -
In the
Format assection, selectTable. -
Adjust elements of the table as required, and click
Applyto save your graph to the dashboard.
Compress your data using hypercore
is the hybrid row-columnar storage engine in used by . Traditional databases force a trade-off between fast inserts (row-based storage) and efficient analytics (columnar storage). eliminates this trade-off, allowing real-time analytics without sacrificing transactional capabilities. dynamically stores data in the most efficient format for its lifecycle:- Row-based storage for recent data: the most recent chunk (and possibly more) is always stored in the , ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a writethrough for inserts and updates to columnar storage.
- Columnar storage for analytical performance: chunks are automatically compressed into the , optimizing storage efficiency and accelerating analytical queries.
Optimize your data in the columnstore
To compress the data in thecrypto_ticks table, do the following:
- Connect to your In open an SQL editor. The in-Console editors display the query speed. You can also connect to your using psql.
-
Convert data to the :
You can do this either automatically or manually:
-
Automatically convert chunks in the to the at a specific time interval:
-
Manually convert all chunks in the to the :
-
Automatically convert chunks in the to the at a specific time interval:
-
Now that you have converted the chunks in your to the , compare the
size of the dataset before and after compression:
This shows a significant improvement in data usage:
Take advantage of query speedups
Previously, data in the was segmented by thesymbol column value.
This means fetching data by filtering or grouping on that column is
more efficient. Ordering is set to time descending. This means that when you run queries
which try to order data in the same way, you see performance benefits.
- Connect to your In open an SQL editor. The in-Console editors display the query speed.
-
Run the following query:
Performance speedup is of two orders of magnitude, around 15 ms when compressed in the and 1 second when decompressed in the .